Ariel University
Course name: Deep learning and natural language processing
Course number: 7061510-1
Lecturer: Dr. Amos Azaria
Edited by: Moshe Hanukoglu
Date: First Semester 2018-2019
Based on presentations by Dr. Amos Azaria
Table of contents
Linear Regression
The task we want to do now is predicting missing information based on information we have that is close to the information we lack.
The method we use is called "Linear regression".
We will take an example problem so that we will have more rest to demonstrate the solution.
Our problem is to predict the price of the Galaxy 5 number phones.
We know prices of Galaxy number 2,3,4,6,7.
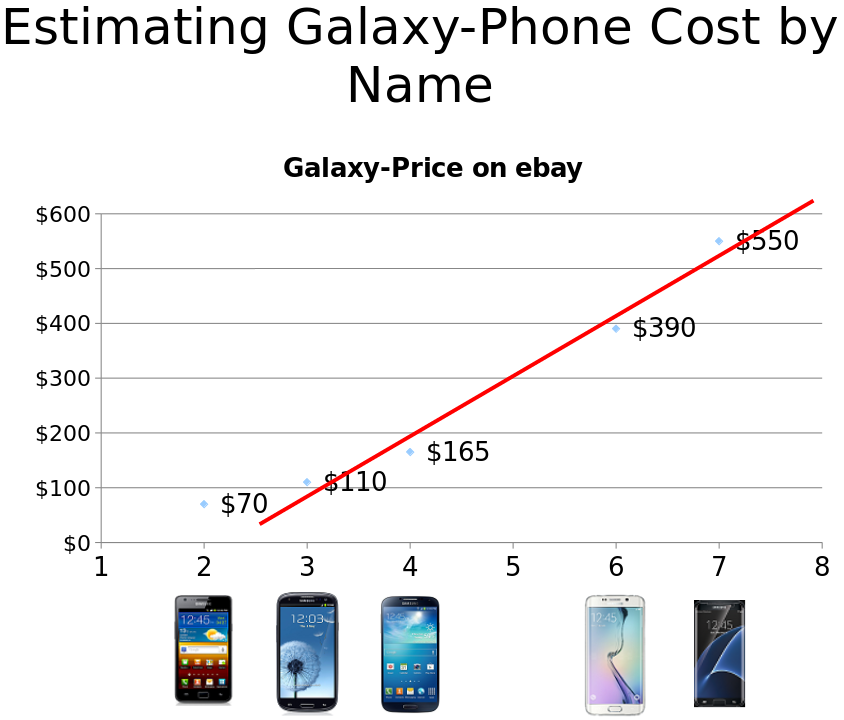
Linear regression is a method that searches for the straight y = wx + b so that the mean of the distances of the straight from each of the points on the graph is minimal.
The red line in the picture above is the one we are looking for.
Formally, each value of $ x \in \{x_1,x_2,x_3,…x_m\}$(Galaxy number) has a value of $ y \in \{y_1,y_2,y_3…y_m\} $ (its price).
For each $ x_i $ and $ y_i $, $ y_i = w x_i + b $.
We will essentially want to achieve the minimum function $ \frac{1}{m} * $$\sum_{i=1}^{m} |wx_i + b - y_i| $.
The minimum is found by the gradient descent.
For ease of work, we will change the function a bit and write it down like this: $ \frac{1}{2m} * $$\sum_{i=1}^{m} \left(wx_i + b - y_i\right)^2 $
Our task is to find the w and b that give us the minimum of the function.
Motivation To Loss Function
We would like to show that the y values we have in dataset are the real values or very close to real values with little "noise", rather than values obtained as a result of a lot of noise entering the results.
In other words, suppose the noise is divided by Gaussian with mean 0 and variance ...
Therefore, the formula is $ \epsilon \sim N(0,\sigma^2) $.
The Gaussian distribution can be said $ p(\epsilon_i) = \frac{1}{\sqrt{2\Pi}\sigma}e^{-\frac{(\epsilon_i)^2}{2{\sigma}^2\\}} $
And therefore will also take place $ p(y_i|x_i;w,b) = \frac{1}{\sqrt{2\Pi}\sigma}e^{-\frac{(y_i - (wx_i+b))^2}{2{\sigma}^2\\}} $
As a result of all this we want to maximize the probability $ p(y|x;w,b) $ to say that the probability of getting yi given $x_i, w, n$ is the highest, which means that the data we received is the most likely, and not that it is reasonable but with a lot of noise.
$$ p(y|x;w,b) = \prod_{i=1}^{m} p(y_i|x_i;w,b) = \prod_{i=1}^{m} \frac{1}{\sqrt{2\Pi}\sigma}e^{-\frac{(y_i - (wx_i+b))^2}{2{\sigma}^2\\}} $$
We will apply log on both wings.
$$ log(p(y|x;w,b)) = log \left(\prod_{i=1}^{m} \frac{1}{\sqrt{2\Pi}\sigma}e^{-\frac{(y_i - (wx_i+b))^2}{2{\sigma}^2\\}}\right) = \sum_{i=1}^{m} log\left(\frac{1}{\sqrt{2\Pi}\sigma}e^{-\frac{(y_i - (wx_i+b))^2}{2{\sigma}^2\\}}\right) = m log\left(\frac{1}{\sqrt{2\Pi}\sigma}\right) + \sum_{i=1}^{m} log\left(e^{-\frac{(y_i - (wx_i+b))^2}{2{\sigma}^2\\}}\right) = m log\left(\frac{1}{\sqrt{2\Pi}\sigma}\right) - \sum_{i=1}^{m} \frac{(y_i - (wx_i+b))^2}{2{\sigma}^2\\}$$
Because $$ log\left(\frac{1}{\sqrt{2\Pi}\sigma}\right) $$ is constant, then to get the greatest value we want $$ \sum_{i=1}^{m} \frac{(y_i - (wx_i+b))^2}{2{\sigma}^2\\} = \frac{1}{2{\sigma}^2\\}\sum_{i=1}^{m} (y_i - (wx_i+b))^2$$ to be as small as possible (because it is negative)
So we calculate the gradient in its negative direction.
Note: In order to understand more deeply the motivation for this function, you can read this link
Note: Linear regression has a closed-form solution $ W = (X^TX)^{-1}X^TY $
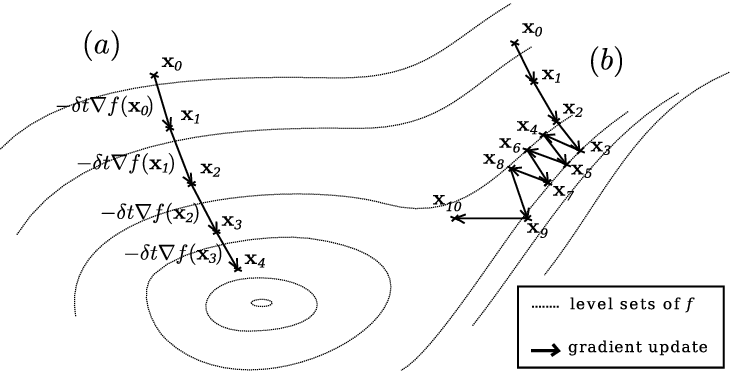
Gradient Descent
Our way of finding the minimum of function is by Gradient Descent.
In this method we calculate the gradient.
The gradient gives us the direction of the incline upwards, so to get the minimum direction we need to multiply -1.
As can be seen in the picture.
 Credit: link
Credit: link
Now we calculate the gradient of our function, $ J(w,b) = \frac{1}{2m} * $$\sum_{i=1}^{m} (wx_i + b - y_i)^2 $.
$ \bigtriangledown J(w,b) = (\frac{\partial J}{\partial w}, \frac{\partial J}{\partial b})$
$\frac{\partial J}{\partial w} = \frac{1}{2m} * $$\sum_{i=1}^{m} 2(wx_i + b - y_i)*x_i = \frac{1}{m} * $$\sum_{i=1}^{m} (wx_i + b - y_i)*x_i$
$\frac{\partial J}{\partial b} = \frac{1}{2m} * $$\sum_{i=1}^{m} 2(wx_i + b - y_i)*1 = \frac{1}{m} * $$\sum_{i=1}^{m} (wx_i + b - y_i)$
$ \bigtriangledown J(w,b) = \left(\frac{1}{m} * \sum_{i=1}^{m} (wx_i + b - y_i)*x_i, \frac{1}{m} * \sum_{i=1}^{m} (wx_i + b - y_i)\right)$
When we have the gradient we can write out an algorithm to linear regression.
Upload the data of Galaxy prices.
import numpy as np
galaxy_data = np.array([[2,70],[3,110],[4,165],[6,390],[7,550]])
Inetialise the w, b and alpha (learning rate).
w = 0
b = 0
alpha = 0.01
We run 10000 epochs when each epoch calculate the gradient and adds it to w, b.
After all 200 epochs printed on the screen the number of iteration, the gradient of w, the gradient of b, the new value of w and the new value of b.
for iteration in range(10000):
gradient_b = np.mean(1*(galaxy_data[:,1]-(w*galaxy_data[:,0]+b)))
gradient_w = np.mean(galaxy_data[:,0]*(galaxy_data[:,1]-(w*galaxy_data[:,0]+b)))
b += alpha*gradient_b
w += alpha*gradient_w
if iteration % 200 == 0 :
print("it:%d, grad_w:%.3f, grad_b:%.3f, w:%.3f, b:%.3f" %(iteration, gradient_w, gradient_b, w, b))
After we have the correct w, b we can recognise the price of Galaxy 5.
print("Estimated price for Galaxy S5: ", w*5 + b)
The three approaches that will be presented later differ in their opinion of how each percentage of the data calculates the gradient each iteration.
- Batch Gradient Descent (BGD): uses all Data-set to compute gradient at a time. Performs an average of all the data and then calculate the gradient.
- Stochastic Gradient Descent (SGD): uses only a single example at a time (shuffle data first).
- Mini-Batch Gradient Descent (MB-GD): uses only a subset of the data-set, (e.g. 50) at a time (requires shuffle as well).
Adding Features
So far we have used one feature for each value.
In order to make our prediction results more accurate, we would like to add more features.
The addition of the features can be done using two methods,
- A natural method to introduce more features to the system on each of the values.
- An artificial method takes the existing feature x and adds other features $ x^2, x^3, ...$
When there are $ n $ features need weight for each feature and therefore there will be $ n $ weights
Create a table in size 2 on n, n will be determined later in the program and initialize W to table in size 2X1 because there are 2 features for each point in the train data.
In this case, we added features by an artificial method.
import tensorflow as tf
import numpy as npfeatures = 2
x = tf.placeholder(tf.float32, [None, features])
y_ = tf.placeholder(tf.float32, [None, 1])
W = tf.Variable(tf.zeros([features,1]))
b = tf.Variable(tf.zeros([1]))
data_x = np.array([[2,4],[3,9],[4,16],[6,36],[7,49]])
data_y = np.array([[70],[110],[165],[390],[550]])
initialize the loss function and update function that runs the gradient descent with alpha 0.001 and our loss function.
y = tf.matmul(x,W) + b
loss = tf.reduce_mean(tf.pow(y - y_, 2))
update = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(100000):
sess.run(update, feed_dict = {x:data_x, y_:data_y})
if i % 10000 == 0 :
print('Iteration:' , i , ' W:' , sess.run(W) , ' b:' , sess.run(b), ' loss:', loss.eval(session=sess, feed_dict = {x:data_x, y_:data_y}))
The actual price of Galaxy 5: $250
print('Prediction for Galaxy 5:', np.matmul(np.array([5,25]),sess.run(W)) + sess.run(b))
The actual price of Galaxy 1: $30
print('Prediction for Galaxy 1:', np.matmul(np.array([1,1]),sess.run(W)) + sess.run(b))
Over Fitting
Over-Fitting is a problem that is created when we add too many attributes because when there are too many features, the model learns to predict precisely the information it is trained on, but when you introduce new information that it did not see, it doesn't know to predict it.
At the end of the program, we see a graph that describes the over-fitting in the price of Galaxy 8, the price is under 0$
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as pltdef vecto(x):
# This function returns an array of numbers with 20 (#features) features.
ret = []
for i in suff_feat:
ret.append(x**i / 7.**i)
return retfeatures = 20
suff_feat = np.array(range(1,features+1))
np.random.shuffle(suff_feat)x = tf.placeholder(tf.float32, [None, features])
y_ = tf.placeholder(tf.float32, [None, 1])
W = tf.Variable(tf.zeros([features,1]))
b = tf.Variable(tf.zeros([1]))
y = tf.matmul(x,W) + b
loss = tf.reduce_mean(tf.pow(y - y_, 2))
update = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
data_x = np.array([vecto(2),vecto(3),vecto(4),vecto(6),vecto(7)])
data_y = np.array([[70],[110],[165],[390],[550]])
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(0,1000000):
sess.run(update, feed_dict = {x:data_x, y_:data_y})
if i % 100000 == 0 :
print('Iteration:' , i , ' W:' , sess.run(W) , ' b:' , sess.run(b), ' loss:', loss.eval(session=sess, feed_dict = {x:data_x, y_:data_y}))
After weight training W and value b we will try to see the predicted value of the model for each of the numbers in the range [0,8].
After we draw them on a graph, the value of 8 appears to be below 0, but the values between 1 and 7 appear to be correct. This means that the system has learned to predict only values in the range that was in practice, but what was not in the training model does not know at all predict.
Now it is possible to visualize the effects of over-fitting.
x_axis = np.arange(0, 8, 0.1)
x_data = []
for i in x_axis:
x_data.append(vecto(i))
x_data = np.array(x_data)
y_vals = np.matmul(x_data, sess.run(W)) + sess.run(b)plt.plot(x_axis, y_vals)
plt.show()

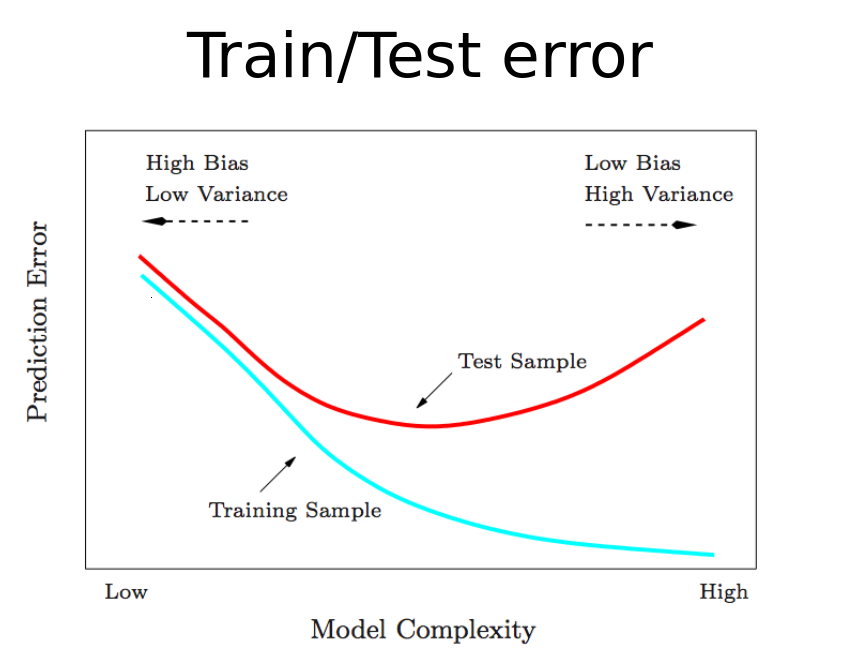
To avoid the problem of over-fitting we will want to find the right balance between the amount of training and predicting the results.
That is, not to train too little or to train too much.
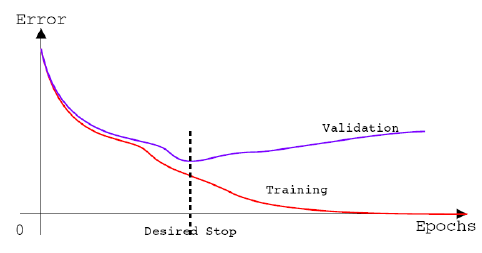
As can be seen in the picture below, we would like to find the minimum "Test sample".
Regularization
In order to deal with over-fitting there are several methods (link).
We will now look at several methods.
This method is to change the loss function.
This method has two ways, one of Lasso and the other of Ridge.
- Lasso: more aggressive towards smaller weights, so many end-up zero.
$ J(w,b) = (\frac{1}{2m} * \sum_{i=1}^{m} (Wx_i + b - y_i)^2)+\lambda{||W||}_1 $.
where $ {||W||}_p = (\sum_{i=1}^{k} |w_i|^p)^{\frac{1}{p}} $ - Ridge: more aggressive towards bigger weights, many weights may end-up being small, but not zero.
$ J(w,b) = (\frac{1}{2m} * \sum_{i=1}^{m} (Wx_i + b - y_i)^2)+\frac{\lambda}{2}({||W||}_2)^2 $.
where $ {||W||}_p = (\sum_{i=1}^{k} |w_i|^p)^{\frac{1}{p}} $
In order for RIDGE to work we need to change the loss function to
loss = tf.reduce_mean(tf.pow(y - y_, 2)) + 0.1\*tf.nn.l2_loss(W)
Note: tf.nn.l2_loss(W) = tf.reduce_sum(W**2)/2.
In the equation of Lasso there is a problem with the derivation because there is an absolute value in his lust, which makes it harder for us to cut and therefore we will use another method to realize his code.
from sklearn import linear_model
import numpy as np
import matplotlib.pyplot as pltdef vecto(x):
ret = []
for i in range(1,21):
ret.append(x**i / 7.**i)
return ret
Displaying an array of weights
clf = linear_model.Lasso(alpha=0.1)clf.fit([vecto(2), vecto(3), vecto(4), vecto(6), vecto(7)], [70,110,165,390,550])print(clf.coef_)
The graph looks with less over-fitting than the graph above with 20 features.
x_axis = np.arange(0,8,0.1)
x_data=[]for i in x_axis:
x_data.append(vecto(i))
x_data = np.array(x_data)clf.predict([vecto(1),vecto(2)])y_vals = clf.predict(x_data)plt.plot(x_axis, y_vals)
plt.show()

A second method looks for the minimum of the loss function, which is checked for the validation, every few epocks and saves the votes that give this minimum.
At the end of the run we will return to the minimum we found during the run and take the weights of the model that gave us this good result, the minimum of the loss function.
{kind=link}
Normalization
When we use numbers as features, then there may be a problem that the numbers are too large because the weights will be affected.
So we want to normalize the features. There are two ways to normalize:
- The simple way is to divide all the numbers with the largest value, so we always get numbers that are in the range [-1,1].
- We subtract the mean number from each number and divide by their standard deviation.
Another type of problems we focus on now is classification.
In this type of problem we will obtain information that is divided again into X and Y, where X is the features and Y is the X classes.
That is we will want to predict the class of $ x_i $.
For example, there are two types of circles, black and white, with different features.
Then we want each new circle we have not seen before and we see its features now for the first time we know whether it is black or white.
Logistic regression solves only classification problems that there are only two classes.
Suppose that one class 0 and 1 this second class.
According to the assumption we will have to actually find a function that gives values in the range [0,1].
We will select the Sigmoid function, and in our case it will look like this $ h(x) = \dfrac{1}{1 + e^{-(xW+b)}} $
A prediction of 1 will mean that we are certain that the value is 1.
We want to make the following two equations exist:
- $ p(y_i = 1|x_i;W,b) = h(x_i) $
- $ p(y_i = 0|x_i;W,b) = 1 - h(x_i) $
In general, we want that $ p(y_i|x_i;W,b) = {h(x_i)}^{y_i}(1 - h(x_i))^{1 - y_i} $. We can see that this equation is correct when we set y to 0 or 1.
Motivation To Loss Function
We want to maximize the probability $ p(y|x;w,b) $ to say that the probability of getting yi given $x_i, w, n$ is the highest, which means that the data we received is the most likely, and not that it is reasonable but with a lot of noise.
$$ p(y|x;w,b) = \prod_{i=1}^{m} p(y_i|x_i;w,b) = \prod_{i=1}^{m} {h(x_i)}^{y_i}(1 - h(x_i))^{1 - y_i} $$
We will apply log on both wings.
$$ log(p(y|x;w,b)) = log\left(\prod_{i=1}^{m} {h(x_i)}^{y_i}(1 - h(x_i))^{1 - y_i}\right) = \sum_{i=1}^{m} log\left( {h(x_i)}^{y_i}(1 - h(x_i))^{1 - y_i}\right) = \sum_{i=1}^{m} {y_i log(h(x_i)) + (1 - y_i) log(1 - h(x_i)))} $$
$$ J(W,b) = -\frac{1}{m}\sum_{i=1}^{m} {y_i log(h(x_i)) + (1 - y_i) log(1 - h(x_i)))} $$
Gradient Descent
Note: The derivative of the Sigmoid function $ h'(x) = \left(\dfrac{1}{1 + e^{-(xW+b)}}\right)' = h(x)(1-h(x)) $
$ \frac{\partial J}{\partial w_i} = ... = \frac{1}{m} \sum_{i=1}^{m} {(y_i - h(x_i))*x_{i,j}} $
We get exact same gradient $ \frac{1}{m} \sum_{i=1}^{m} x_{i}{(h(x_i) - y_i)} $
Example of Classification
We will show code as an example of classification, the example will be classifying a text message to urgent / non-urgent, based on its words.
In order to present the solution, we will bring some explanations.
When we have a very large database with lots of features and all $x_i$ has only some features and we want to know what features are in each of $x_i$, then the method is to create an array the size of the features and mark 1 in the index $i$ to say that feature $i$ is in $x_i$, twice we will write 2, etc. This method is called Bag-of-Words Model.
We will use this method even when we have a dataset of sentences and want to know which word appears in each sentence and how many times it appears in the sentence, we will build an array the size of the number of quantity different words together in sentences.
import nltk
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenizeimport tensorflow as tfimport numpy as np
vocabulary_size = 0 #can use "global" keyword
word2location = {}
ps = PorterStemmer()def prepare_vocabulary(data):
idx = 0
for sentence in data:
for word in word_tokenize(sentence):
if ps.stem(word) not in word2location:
word2location[word] = idx
idx += 1
return idxdef convert2vec(sentence):
res_vec = np.zeros(vocabulary_size)
for word in word_tokenize(sentence):
stemmer = ps.stem(word)
if stemmer in word2location:
res_vec[word2location[stemmer]] += 1
return res_vec
data = ["Where are you? I'm trying to reach you for half an hour already, contact me ASAP I need to leave now!",
"I want to go out for lunch, let me know in the next couple of minutes if you would like to join.",
"I was wondering whether you are planning to attend the party we are having next month.",
"I wanted to share my thoughts with you."]
vocabulary_size = prepare_vocabulary(data)
print(convert2vec(data[1])) # "I want to go out for lunch, let me know in the next couple of minutes if you would like to join."
features = vocabulary_size
eps = 1e-12
x = tf.placeholder(tf.float32, [None, features])
y_ = tf.placeholder(tf.float32, [None, 1])
W = tf.Variable(tf.zeros([features,1]))
b = tf.Variable(tf.zeros([1]))
Adding an epsilon is required especially because we have W = 0 and b = 0, and the log function should not receive 0.
y = 1 / (1.0 + tf.exp(-(tf.matmul(x,W) + b)))
loss1 = -(y_ * tf.log(y + eps) + (1 - y_) * tf.log(1-y + eps))
loss = tf.reduce_mean(loss1)
update = tf.train.GradientDescentOptimizer(0.00001).minimize(loss)
x_data is the display of the output "convert2vec" for each sentence.
y_data is the urgent / non-urgent type of sentence where 1 is urgent and 0 is non-urgent
data_x = np.array([convert2vec(data[0]), convert2vec(data[1]), convert2vec(data[2]), convert2vec(data[3])])
data_y = np.array([[1],[1],[0],[0]])
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(0,10000):
sess.run(update, feed_dict = {x:data_x, y_:data_y})
After we created the program that learns to identify the types of sentences, now we will try to examine its results.
In order for the model to work with high accuracy, of course, the dataset is much larger.
def logistic_fun(z):
return 1/(1.0 + np.exp(-z))test1 = "I need you now! Please answer ASAP!"#pdb.set_trace()
print('Prediction for: "' + test1 + '"', logistic_fun(np.matmul(np.array([convert2vec(test1)]),sess.run(W)) + sess.run(b))[0][0])
The Quality of The Classifier
There are several indices for checking the accuracy of a classifier. Each indice shows the accuracy of another field.
We can understand the metrics by the following table:
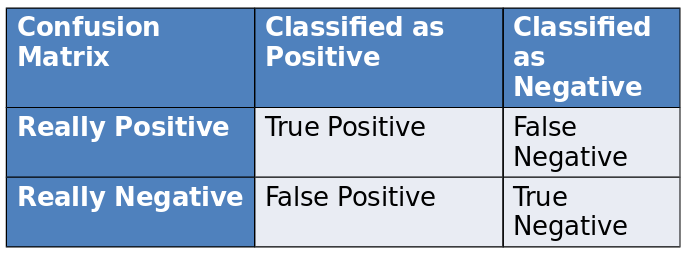
The indices are:
- Accuracy = $\frac{Trues}{All}$: $\frac{True Positive + True Negative}{True Positive + True Negative + False Negative + False Positive}$
- Recall = What fraction of positives did we actually find: $\frac{True Positive}{True Positive + False Negative}$
- Precision = If we say positive, how precise are we: $\frac{True Positive}{True Positive + False Positive}$
- F-Measure: $2\frac{Precision * Recall}{Precision + Recall}$
Imbalanced Data
One of the difficulties in creating a valid dataset is to create it so that the data is balanced so there will be few examples from one class and much from another.
But even if we devoured an unbalanced dataset we could use it.
We'll show some solutions how to use it correctly.
For the convenience of the explanation it is said that there is 1% class and 99% of the second class.
(Note: all the numbers shown for the imbalance are spoken after the division into the train and test, if not then divided into a train and a test, where each of the data for each class is divided by the example of 7:3.)
- Compare the amount of data from each class by taking each class as much information as the class information with the least amount of information.
- Each epoch will take 1% randomly from the 99% and actually we will have 1% of the first class and 1% of the second class.
- Divide 99% to 99 times 1% and each of them attach the 1% of the small class.
- In this method, we will not change the dataset structure, but we will change our attitude toward predictive errors for examples of the small class, ie we will "penalize" the model more strongly for predicting error in the small class.
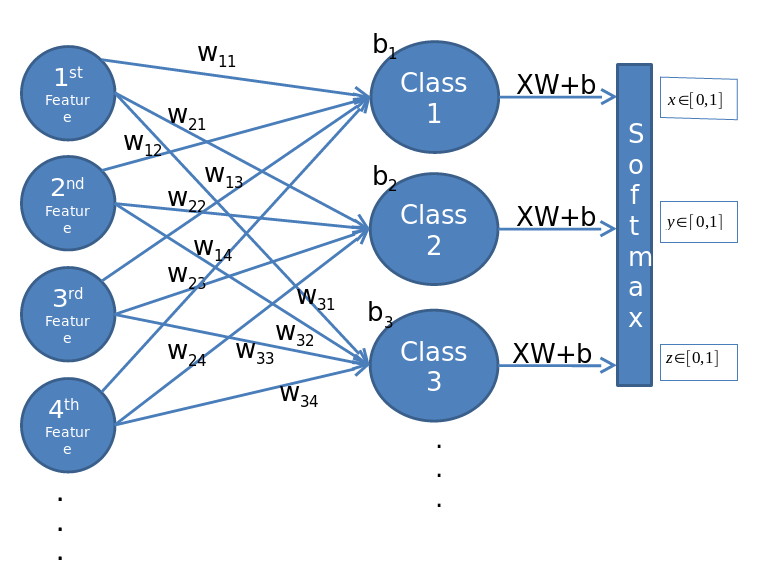
Multiple Classes (SoftMax)
So far, we have been dealing with classifications that have two departments, but we do not always have only two departments. Sometimes we have more, but we still want to classify the departments.
So far, we have been dealing with classifications that have two departments, but we do not always have only two departments.
Sometimes we have more, but we still want to classify the departments.
For example, if we have 4 classes A, B, C, D and we have an object that belongs to class C, then we say [0,0,1,0]
Given $x_i$, we would like to know which class it belongs to, so we will use the following formula and check the result for each department and select the class with the maximum value.
$$ h(y = i|x) = \frac{e^{x^TW_i+b_i}}{\sum_{j=1}^{k} {e^{x^TW_j+b_j}}} $$
Where: $ x $ is an array that represents all the values of the features of $ x $,
$ W_i $ is one line from the $W$ matrix.
The columns of matrix $W$ represent the features and the rows represent the classes.
Ie $W_{i,j}$ represents the weight of feature $i$ in class $j$
Note: $ \sum_{i\in\{1,2,...,k-1\}} {h(y = i|x)} = 1 $
Note: W is a matrix where each row is a class and each column is a property.
Note: Logistic regression is a private case of softmax, which means softmax that has only two classes.
The loss function of softmax is: loss = -tf.reducemean(y*tf.log(y)), where y_ and y are both vectors.
Now look at an example of using softmax:
Example - SMS Classification
We present a program that classifies SMS messages into three different departments
- Finance
- Work
- Family & Friends
We will use Bag-of-Words Model.
import nltk
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenizeimport tensorflow as tfimport numpy as np
vocabulary_size = 0 #can use "global" keyword
word2location = {}
ps = PorterStemmer()def prepare_vocabulary(data):
idx = 0
for sentence in data:
for word in word_tokenize(sentence):
if ps.stem(word) not in word2location:
word2location[word] = idx
idx += 1
return idxdef convert2vec(sentence):
res_vec = np.zeros(vocabulary_size)
for word in word_tokenize(sentence):
stemmer = ps.stem(word)
if stemmer in word2location:
res_vec[word2location[stemmer]] += 1
return res_vec
Counting the number of features, that is, the amount of words in a dictionary.
data = [
"Your auto payment of $50 was charges successfully!",
"You have received a refund of $20",
"Please complete your power point presentation by tomorrow.",
"You must arrive on time tomorrow, otherwise the manager will want to talk to you",
"How about celebrating Bob's birthday party next week?",
"Everyone is waiting for you at home, please come home early!"]
vocabulary_size = prepare_vocabulary(data)
The training phase of the model
features = vocabulary_size
categories = 3
x = tf.placeholder(tf.float32, [None, features])
y_ = tf.placeholder(tf.float32, [None, categories])
W = tf.Variable(tf.zeros([features,categories]))
b = tf.Variable(tf.zeros([categories])) # One b for each classy = tf.nn.softmax(tf.matmul(x, W) + b)
loss = -tf.reduce_mean(y_*tf.log(y))update = tf.train.GradientDescentOptimizer(0.00001).minimize(loss)
Create the data for training as above
data_x = np.array([convert2vec(data[i]) for i in range(len(data))])
data_y = np.array([[1,0,0],[1,0,0],[0,1,0],[0,1,0],[0,0,1],[0,0,1]])sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(0,10000):
sess.run(update, feed_dict = {x:data_x, y_:data_y})
The testing phase of the model
test1 = "Your payment has been received, no refund is currently available."
test2 = "The manager said that your presentation went well, but next time make sure to arrive on time."
test3 = "We are all waiting for you at the birthday party!"print('\nPrediction for: "' + test1 + ': "', sess.run(y, feed_dict={x:[convert2vec(test1)]}))
print('\nPrediction for: "' + test2 + ': "', sess.run(y, feed_dict={x:[convert2vec(test2)]}))
print('\nPrediction for: "' + test3 + ': "', sess.run(y, feed_dict={x:[convert2vec(test3)]}))
IMPORTANT NOTE: Because the computer can only represent up to a certain level of precision, then when we want to represent a number with higher accuracy, the computer will round the numbers, that is, if we have a very close to 0 and use log on the number, The computer will turn the number to 0 and get we an error (since log 0 is not set).
In order to deal with such problems, we will always prefer to use functions that are implemented by TensorFlow.
- tf.nn.sigmoid(tf.matmul(x,W) + b)
- tf.nn.sigmoid_cross_entropy_with_logits()
- tf.nn.softmax_cross_entropy_with_logits_v2()
Summary
After we saw how to realize the logistic regression and the softmax, we now see the structure of the model that we are building visually.
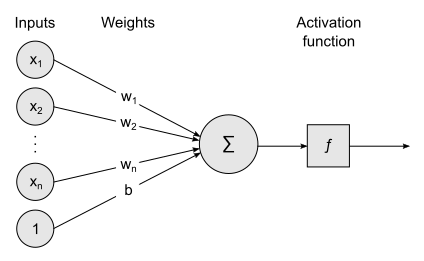
Where activation function is sigmoid and $x_i$ is the feature $i$.